Scene Representation Group


















Our goal is to build AI systems that autonomously learn to understand and interact with the physical world. We achieve this by creating agents that build internal world models, allowing them to simulate future events and predict the consequences of their actions.
As humans, we constantly reconstruct a mental representation of our surroundings from sensory input—capturing geometry, materials, mechanics, and dynamical processes. This allows us to navigate, plan, and act effectively. Humans acquire this skill with minimal supervision, learning primarily through self-play and observation.
We aim to endow machines with these same computational capabilities. How can agents learn intuitive physics—how objects move and interact—or the fact that our world is 3D, solely through interaction? How can they acquire new concepts from a single demonstration? What intrinsic motivation drives exploration? To answer these questions, our research develops methods across representation learning, generative modeling, and planning.
Recent Publications view all
Large Video Planner
Generative View Stitching
True Self-Supervised Novel View Synthesis is Transferable
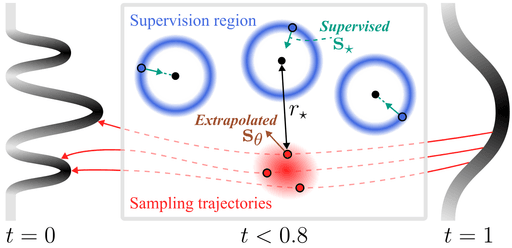
Selective Underfitting in Diffusion Models